One Governance, Many Orchestrators
Everyone is comparing CLAUDE.md vs Cursor rules vs AGENTS.md. That is the wrong question. The right question is: where does your governance live, and how does every AI tool respect it?
Your team uses Cursor for most development work. A few engineers prefer Claude Code. Someone just started using GitHub Copilot in VS Code. Another team member is evaluating Windsurf.
Each tool has its own configuration format. Cursor uses .cursor/rules/ with .mdc files. Claude Code reads CLAUDE.md. GitHub Copilot looks for .github/copilot-instructions.md. Windsurf wants .windsurfrules. And now the Agentic AI Foundation (AAIF) under the Linux Foundation is pushing AGENTS.md as the universal standard, with Anthropic, OpenAI, Google, and Microsoft as founding members.
The internet is full of articles comparing these formats. Which one should you use? Which one wins? Every article frames this as a file format decision.
It is not a file format decision. It is an architecture decision.
Our team runs multiple AI orchestrators across multiple repositories in production. We maintain 40+ governance rules, enforce compliance on every task, and have not duplicated a single rule across tools. Here is how.
The File Format Explosion
As of March 2026, the landscape looks like this:
| Tool | Native Format | AGENTS.md |
|---|---|---|
| Cursor | .cursor/rules/*.mdc | Supported |
| Claude Code | CLAUDE.md | Supported |
| GitHub Copilot | .github/copilot-instructions.md | Supported |
| OpenAI Codex | AGENTS.md (origin) | Native |
| Windsurf | .windsurfrules | Supported |
| Gemini CLI | GEMINI.md | Supported |
| Devin, goose, Amp, Aider | Various | Supported |
Seven tools, seven native formats, one emerging universal standard. If you maintain a separate governance file for each tool, you are managing seven copies of the same intent. Every update requires editing multiple files. Every new team member sees a different version of reality depending on which tool they open.
The AAIF recognized this problem. AGENTS.md is their answer: one file that every tool reads. Adopted by over 60,000 open-source projects. OpenAI's own repository contains 88 of them. It is the right instinct -- a universal standard beats fragmented tool-specific files. But it is a starting point, not a solution.
Why Format Comparison Misses the Point
The articles comparing these formats treat governance as a delivery problem: how do I get instructions into the AI's context window? That is a solved problem. Every tool reads markdown. Every tool supports project-level configuration. The delivery mechanism is not where teams struggle.
Teams struggle with what the files say, not where they live.
As I wrote in Documentation Is Not Governance, monolithic context files that describe what the codebase looks like actively harm AI performance. ETH Zurich proved this: AGENTS.md files reduced task success rates by 3% and increased inference cost by over 20%. Vercel's own evaluation showed that AI skills (on-demand context retrieval) performed no better than having no documentation at all -- the agent ignored them 56% of the time.
But Vercel also showed that a carefully compressed 8KB docs index in AGENTS.md achieved a 100% pass rate. The difference was not the file format. It was the content architecture -- what went in the file and how it was structured.
The real question
Three Strategies (and Which One Scales)
Teams approaching multi-tool governance land on one of three strategies. I have used all three. Only one scales.
Strategy 1: Parallel Maintenance
Write separate files for each tool. CLAUDE.md for Claude Code, .cursor/rules/ for Cursor, copilot-instructions.md for Copilot. Each file contains the full set of team governance.
Problem: 80%+ duplication. Every rule change requires editing multiple files. Files drift out of sync within weeks. A new team member using Cursor sees different governance than a colleague using Claude Code. This is the path most teams start on. It breaks at five rules. It is unmanageable at forty.
Strategy 2: Symlink Unification
Write AGENTS.md once. Symlink it to CLAUDE.md, .github/copilot-instructions.md, and .cursor/rules/agents.md. One file, zero duplication.
Problem: Lowest common denominator. You lose every tool-specific capability: Cursor's tiered loading, glob-based file scoping, and always-apply configuration. Claude Code's MCP integration settings. Copilot's code review policies. You get consistency by sacrificing the features that make each tool powerful. For small projects with simple governance, this works. For production systems with 40+ rules, you need more.
Strategy 3: Source-of-Truth Architecture
Pick one governance system as the source of truth. Build thin adapters for every other tool. The adapters reference the source of truth, add tool-specific features, and nothing else.
This is what we use in production. Zero duplication, full tool-specific capability, one place to update governance.
The Source-of-Truth Architecture
We use Cursor rules as the single source of truth for governance across all AI tools. Here is why, and how the adapters work.
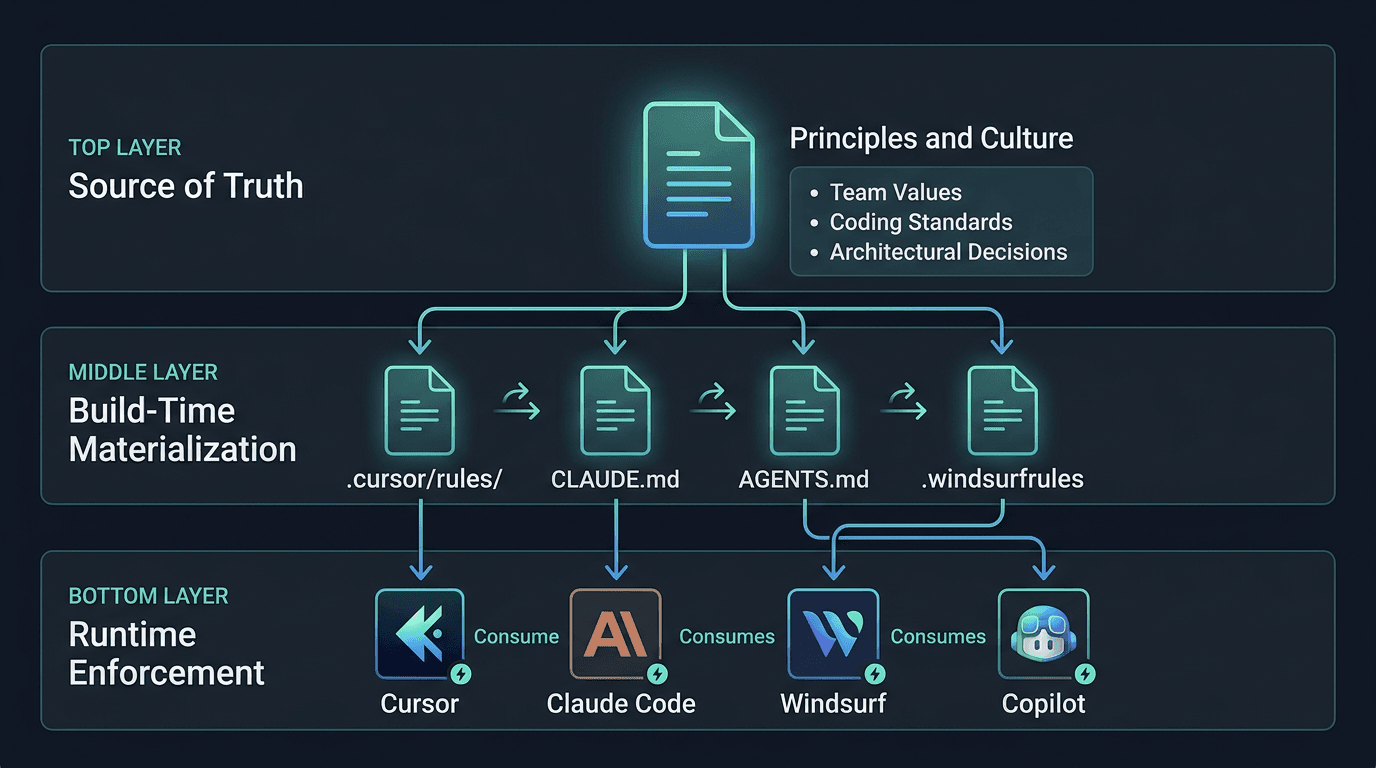
Why Cursor Rules as Source of Truth
Cursor's .mdc format has capabilities that no other format matches:
Tiered Loading
Rules have alwaysApply: true for universal principles (communication standards, simplify before adding) and alwaysApply: false for domain-specific rules (form handling, SDK usage, testing patterns). An agent fixing CSS does not load database optimization rules. AGENTS.md and CLAUDE.md load everything, every time.
Glob-Based Scoping
Rules can target specific file patterns. A rule scoped to **/*.test.ts only activates when the agent works on test files. A rule scoped to apps/my-app/** only applies in that application. No other format offers this precision.
Monorepo-Native Architecture
App-specific rules live in apps/<app>/.cursor/rules/ with their own bootstrap index. Our monorepo has multiple apps, each with its own rules that inherit from workspace-level governance. The agent working in a product-specific app automatically loads that product's brand rules plus universal culture rules.
Enforcement Loops
Our 'Exhaustive Compliance Review' rule triggers at task completion. The agent scans every rule, assesses which ones apply based on what it did, reads each applicable rule, and verifies compliance. The cycle repeats until clean. This is not possible with a passive AGENTS.md that loads and forgets.
The CLAUDE.md Adapter
We use two patterns for CLAUDE.md, depending on the repository's complexity.
Pattern A: Thin Redirect
For our backend repository, CLAUDE.md opens with: “Source of truth: .cursor/rules/bootstrap.mdc. This file exists only for Claude Code sessions.”
It then includes a compressed summary of critical rules, common commands, and key file paths -- enough context for Claude Code to operate effectively while pointing to the full governance system for details.
Pattern B: Full Entry Point
For our frontend monorepo, CLAUDE.md is a comprehensive guide covering the tech stack, app-specific gotchas, and anti-patterns.
It references cursor rules by path for deeper guidance but stands alone as a functional entry point. Useful when the repository is complex enough that a thin redirect would leave Claude Code without sufficient context.
Both patterns follow the same principle: the cursor rules are the source of truth. CLAUDE.md is an adapter that delivers the right slice of governance to Claude Code, not a second copy of governance competing with the first.
The adapter test
.mdc file. The CLAUDE.md adapter inherits the change automatically because it references the rules, not duplicates them.What Goes Where
The practical question is not “which file format” but “what content belongs in which layer.” Here is the breakdown we use:
| Content Type | Where It Lives | Why |
|---|---|---|
| Team principles and culture | Cursor rules (always-apply) | Apply to every task, every tool, every person |
| Domain-specific patterns | Cursor rules (on-demand, glob-scoped) | Load only when relevant, reduces context noise |
| Enforcement and compliance | Cursor rules (always-apply) | Must run at task completion regardless of tool |
| App-specific conventions | App-level cursor rules | Monorepo isolation, auto-loads per directory |
| Critical commands and shortcuts | CLAUDE.md adapter | Claude Code needs quick reference for common operations |
| Cross-tool universal index | AGENTS.md (if adopted) | Thin index for tools that only read AGENTS.md |
The key insight: principles and culture belong in the richest governance system available (cursor rules, with tiered loading and enforcement). Tool-specific adapters carry only what that specific tool needs beyond the source of truth.
Cross-Repository Governance
Multi-tool governance is only half the problem. Real teams work across multiple repositories. Our frontend (TypeScript, Next.js) and backend (Python, Django, FastAPI) codebases have fundamentally different domain rules but share the same culture.
Shared Culture Rules
Communication standards, simplify before adding, stand on the shoulders of giants -- these rules are identical across repositories. Same principle, same wording, same enforcement. A Python developer and a TypeScript developer operate under the same team culture.
Different Domain Rules
'The Model IS the Service Layer' applies to Django. 'Server until proven client' applies to Next.js. Each repository has domain rules that make no sense in the other context. These are not duplicated; they are independently authored for their ecosystem.
The pattern: culture rules are the same across all repositories. Domain rules are unique to each repository. When we update “communication standards,” we update it everywhere. When we add a new Django model pattern, only the backend gets it.
Cross-repo consistency check
The Enforcement Gap Nobody Talks About
Every article about AGENTS.md and CLAUDE.md focuses on loading -- getting context into the AI's window. None of them address the harder problem: verifying that the AI actually followed the rules.
AGENTS.md is a passive document. It loads at session start and then the AI proceeds with no verification. CLAUDE.md is the same. Even Cursor rules in their basic form are just context injection.
The gap is enforcement. We close it with the Exhaustive Compliance Review: an always-apply rule that triggers before any task is declared complete. The agent scans every rule file, decides which ones apply based on what it actually did (semantic judgment, not file-path matching), reads each applicable rule, and verifies compliance. If it finds a violation, it fixes it and starts the cycle over. The task is not done until a full cycle finds zero violations.
The Compliance Cycle
.mdc fileThis works regardless of which tool the agent runs in. The compliance review rule is part of the governance source of truth. In Cursor, it is an always-apply rule. In Claude Code, the CLAUDE.md adapter includes a reference to the same compliance protocol. The enforcement mechanism is tool-agnostic because it is encoded in the governance itself, not in the tool's features.
The AAIF and Where This Is Heading
The Agentic AI Foundation forming under the Linux Foundation is a significant moment. Anthropic, OpenAI, Google, Microsoft, Amazon, and Cloudflare agreeing on a standard is rare. AGENTS.md as a universal baseline is good for the ecosystem.
But AGENTS.md is a file format, not a governance architecture. It solves the delivery problem (how do I get instructions to every tool?) without solving the governance problem (what should those instructions encode, how do they load selectively, and how is compliance enforced?).
My prediction: teams will adopt AGENTS.md as the universal baseline and discover, as we did, that a single flat markdown file is insufficient for production governance. They will add tool-specific files. Then they will face the same architecture decision: parallel maintenance, symlink unification, or source-of-truth with adapters.
The teams that get ahead of this curve will treat AGENTS.md as an adapter -- not the source of truth -- and build their governance in a system that supports the richness their team needs.
What the Comparison Articles Get Wrong
The growing body of content comparing these formats shares three blind spots:
They confuse delivery with governance
Every comparison focuses on how context reaches the AI (passive loading vs on-demand retrieval, token budgets, file formats). None address what the context should encode. A perfectly delivered bad rule is still a bad rule. Governance is about the content, not the transport.
They assume governance is static
“Write your AGENTS.md, drop it in the repo, you are done.” Real governance evolves. Rules are created from discovered violations. Outdated rules are removed. The compliance review catches new patterns. The system compounds over time. None of the format comparison articles discuss the feedback loop that makes governance improve.
They optimize for the wrong metric
Token count, file size, loading speed. These matter at the margins. The metric that actually matters is first-attempt compliance: does the AI produce output that meets team standards without requiring manual correction? A 15KB governance file that eliminates correction cycles is cheaper than a 2KB file that produces work you spend 30 minutes fixing.
How to Get Started
If your team uses multiple AI orchestrators and you are managing governance as separate files per tool, here is a migration path to source-of-truth architecture:
Audit what you have. Read every governance file across every tool. Highlight what is duplicated (this becomes your shared source of truth) and what is tool-specific (this stays in the adapter).
Choose a source of truth. If your team primarily uses Cursor, cursor rules are the natural choice (tiered loading, glob scoping, enforcement). If your team primarily uses a different tool, pick what gives you the richest governance capabilities and build adapters outward.
Separate culture from configuration. Rules that encode why (principles, decision frameworks, team culture) go in the source of truth. Rules that describe what (build commands, file paths, directory trees) go in tool-specific adapters or not at all -- the AI can read the filesystem.
Build the adapters. Each adapter file (CLAUDE.md, AGENTS.md, copilot-instructions.md) should reference the source of truth and add only what that specific tool needs. When you update a rule in the source, the adapters inherit the change.
Add enforcement. Whatever your source of truth system is, add a rule that triggers at task completion and verifies compliance. Without enforcement, governance is suggestion. With enforcement, it is a system that compounds.
Stop Doing
- Maintaining separate governance files per tool
- Treating file format as the primary decision
- Writing rules that describe what the code looks like
- Optimizing for smallest possible token count
- Loading governance and walking away
Start Doing
- Single source of truth with tool-specific adapters
- Encoding principles (why) instead of descriptions (what)
- Tiered loading that matches context to task
- Enforcement at task completion
- Creating new rules from discovered violations
The next AI orchestrator will arrive with its own configuration format. The one after that will too. If your governance lives in the tool, you are rebuilding it every time you switch. If your governance lives in an architecture with adapters, a new tool is a new adapter -- not a new governance system.
Build the governance once. Deliver it everywhere. The tools will keep changing. Your team's principles will not.
Build governance that outlasts any tool
Our team runs 40+ rules across multiple AI orchestrators with zero duplication. If you are building multi-tool governance for your team, I am happy to share what we have learned.