Documentation Is Not Governance
An ETH Zurich study found that AGENTS.md files reduce AI agent performance. They tested documentation. We use governance. The distinction changes everything.
In February 2026, researchers at ETH Zurich published a paper that made the rounds in every AI engineering community: "Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?". The finding was stark: context files like AGENTS.md tend to reduce task success rates while increasing inference cost by over 20%.
The headline conclusion — context files make AI agents worse — has been interpreted broadly. Teams are questioning whether Cursor rules, CLAUDE.md files, and project-level instructions are worth maintaining at all. Some are stripping their repositories bare.
They are drawing the wrong conclusion from the right data.
The paper proved that dumping documentation into an AI's context window does not help. We agree completely. But documentation is not governance. The study tested a specific, narrow format — monolithic markdown files loaded indiscriminately — and the results should not be generalized to principled governance systems that operate at a fundamentally different level.
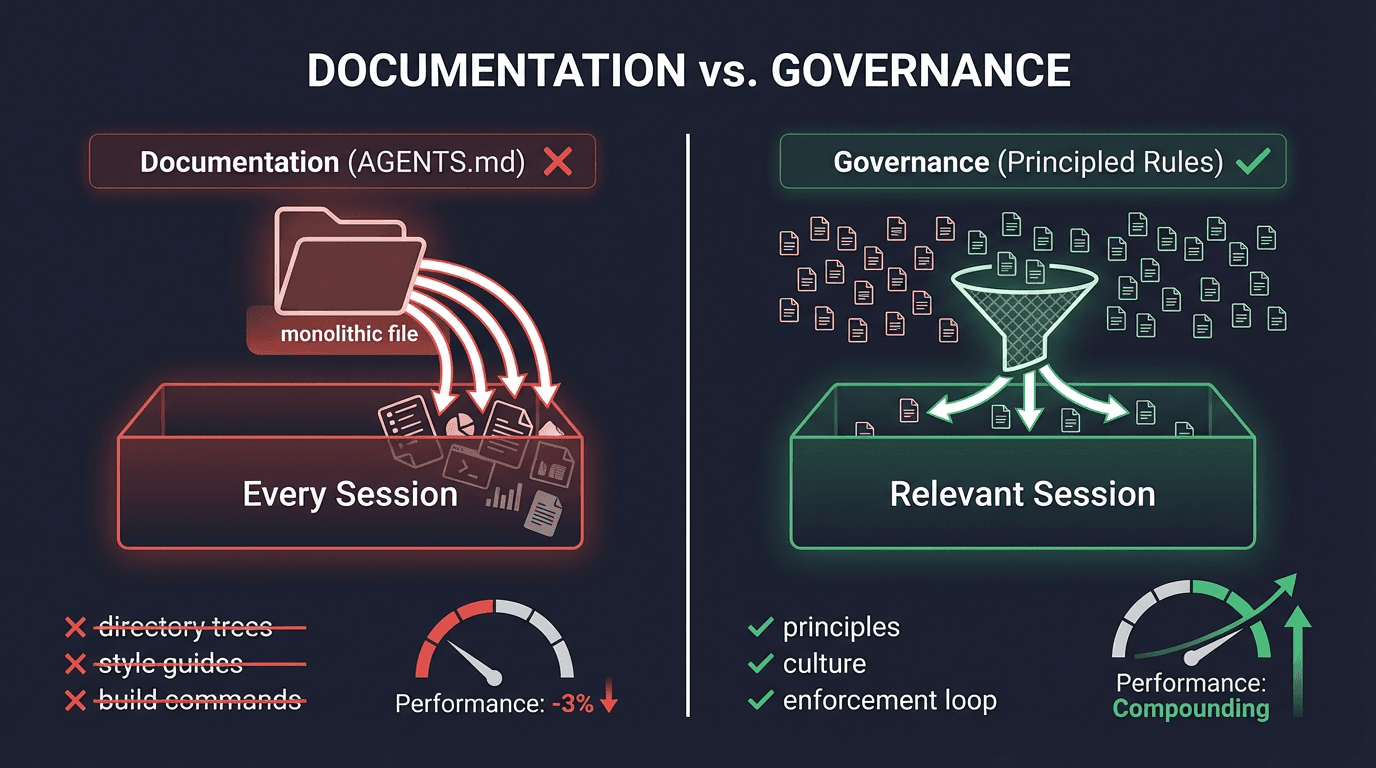
What the Paper Actually Tested
The ETH Zurich team evaluated AGENTS.md files — centralized markdown documents loaded into every agent session — in two settings:
Setting 1: SWE-bench with LLM-Generated Context
Standard bug-fixing tasks from popular open-source repositories, with context files auto-generated by large language models following agent-developer recommendations. Result: success rates dropped by approximately 3%.
Setting 2: AGENTBENCH with Developer-Written Context
A novel benchmark of 138 Python tasks from 12 repositories that already had developer-committed AGENTS.md files. Result: marginal 4% improvement — but inference costs increased by 20%+ across the board.
The behavioral finding is the most interesting part: agents faithfully followed the instructions in these files, even when those instructions made tasks harder. Style guides consumed context tokens. Directory trees duplicated information the agent could discover by reading the filesystem. Architecture overviews added "mental" overhead without guiding decisions.
The Core Finding
This finding is valid. We agree with it. And it is precisely why documentation-style context files fail — they tell the agent what the codebase looks like, which the agent can discover on its own. They do not tell the agent why the team makes the decisions it makes, which the agent cannot discover from code alone.
Where the Paper Is Right
Before challenging the paper's broader conclusions, it is worth acknowledging what it got right. Three findings align directly with our own production experience:
Auto-Generated Context Files Are Noise
LLM-generated summaries of a codebase are redundant by definition. The AI can read the files itself — summarizing them in advance wastes tokens on information the agent already has access to. This aligns with our 'Stand on the Shoulders of Giants' principle: don't reinvent what the framework already provides.
Style Guides Belong in Linters, Not Context
Telling an AI to 'use camelCase' or 'prefer functional components' is token-expensive, ambiguously interpreted, and inferior to deterministic tooling. Our Discipline Stack puts automated verification (type-checking, linting, formatting) in Layer 3 — the machine-enforceable layer. Spending context tokens on what a linter catches for free is waste.
Every Instruction Competes for Attention
The 'lost in the middle' problem is real. Context windows are not infinite storage — they are attention budgets. Every irrelevant rule degrades the agent's focus on what matters. This is why our 'Simplify Before Adding' principle applies to rules themselves: if a rule doesn't earn its context tokens, remove it.
Five Things the Paper Did Not Test
The paper's methodology is rigorous within its scope. The problem is that the scope is narrow — and the conclusions are being applied broadly. Here is what the study did not evaluate.
WHY-Focused Principles vs. WHAT-Focused Documentation
The AGENTS.md files tested were overwhelmingly descriptive: directory structures, build commands, coding conventions, architecture overviews. These describe what the codebase looks like — information the agent can discover by reading it.
Our Cursor rules encode why. "Server until proven client" is not a description of the codebase — it is a principle that generates the correct decision in situations no rule anticipates. "The Model IS the Service Layer" tells the agent where business logic belongs, not where files are located.
As we wrote in The Zen of Frontend: "Rules tell you what to do. Culture tells you how to think." The paper tested rules. It did not test culture.
Selective Loading vs. Monolithic Injection
AGENTS.md is a single file loaded into every session regardless of task relevance. An agent fixing a CSS issue loads database migration guidelines. An agent updating documentation loads performance optimization rules. Every word burns context tokens whether it is relevant or not.
Our system uses tiered loading. Universal principles ("communication standards," "simplify before adding") are always active because they apply to every task. Domain-specific rules (form handling, SDK usage, testing conventions) load on demand when the agent's task requires them. An agent fixing a CSS issue does not load database rules. This is not a subtle difference — it is the difference between a context budget spent wisely and one spent indiscriminately.
Enforcement Loops vs. Passive Documents
The paper treats context files as fire-and-forget: loaded at session start, then the agent proceeds with no verification of compliance. If the agent ignores a rule, nobody notices. If the agent follows a counterproductive rule, nobody corrects it.
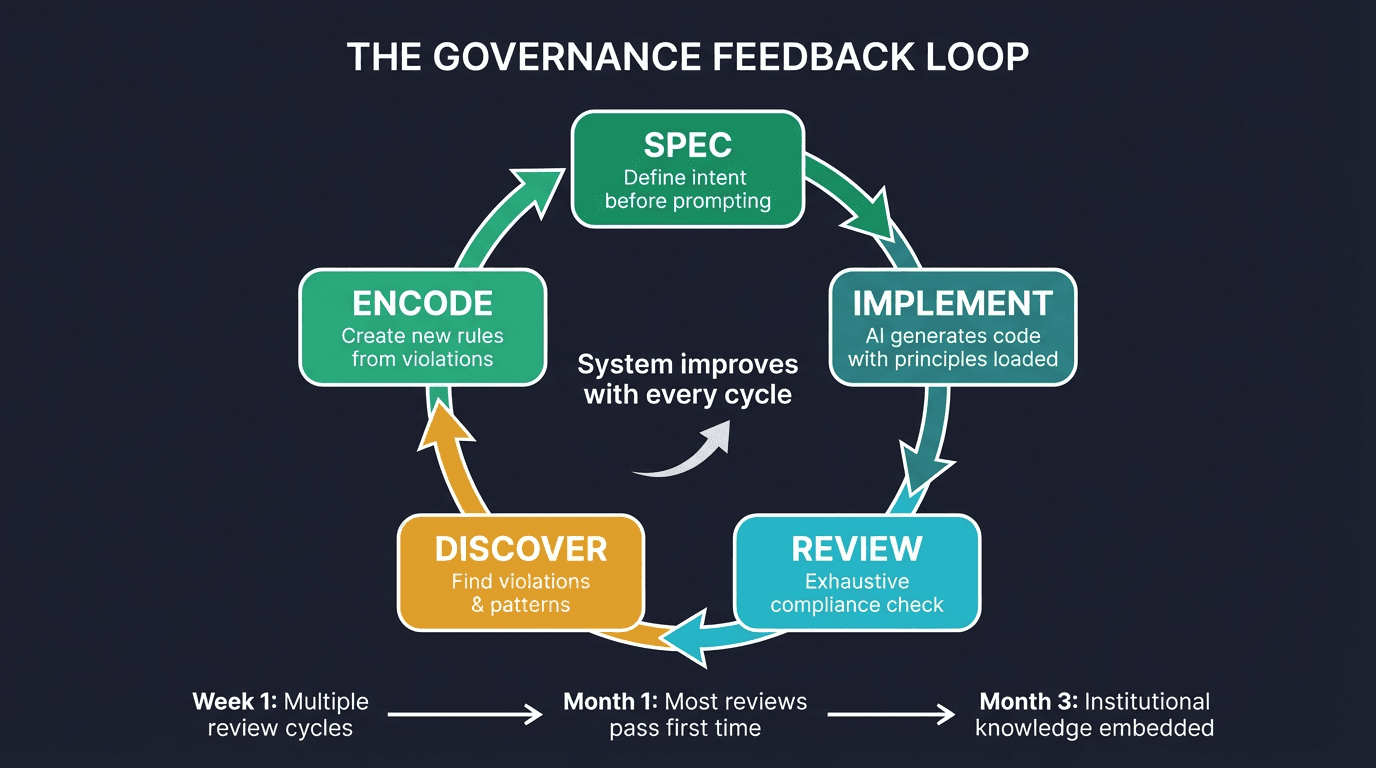
Our system includes an Exhaustive Compliance Review that triggers before any task is declared complete. The agent scans every rule, assesses which ones apply based on what it did (not where files live), reads each applicable rule, and verifies compliance. The cycle repeats until a full pass finds zero violations.
This is the critical difference: AGENTS.md is a suggestion. Our compliance review is enforcement. The paper measured what happens when you give an agent instructions and walk away. It did not measure what happens when you verify compliance and iterate until clean.
Self-Improvement Feedback vs. Static Documents
AGENTS.md files are written once and loaded repeatedly. They do not learn from failures. When a context file causes a problem, the team might edit it eventually — but there is no systematic mechanism for improvement.
Our governance system creates new rules from discovered violations. As we documented in Spec-Driven Development: if the AI makes the same mistake three or more times, encode a rule. The compliance review catches violations; the self-improvement loop prevents them from recurring. After a month of this cycle, most reviews complete in a single pass — the system has internalized the team's standards.
Team Development vs. Isolated Bug Fixes
SWE-bench tasks are isolated bug fixes on open-source codebases the agent has no history with. In this context, documentation files are redundant — the agent needs to read the code to fix the bug regardless. A directory listing does not help you find a null pointer exception.
Our use case is fundamentally different: a cross-functional team building and maintaining a codebase over months, where architectural decisions made six months ago still constrain today's code, where a new contributor needs to know why the team chose one API framework over another, and where designers and product managers contribute alongside engineers. The paper's benchmark cannot measure the value of institutional knowledge transfer because the tasks do not require institutional knowledge.
Documentation vs. Governance: The Architecture Matters
The distinction is not semantic — it is architectural. AGENTS.md and principled governance operate at different levels, solve different problems, and produce different outcomes.
- Single monolithic file per directory
- Describes WHAT: directory trees, build commands, style guides
- Loaded entirely, every session, regardless of task
- No enforcement — passive document
- No feedback loop — static over time
- Tested on bug fixes in unfamiliar open-source repos
- Dozens of rules with tiered selective loading
- Encodes WHY: principles, culture, decision frameworks
- Semantic applicability — load what the task needs
- Exhaustive compliance review at task completion
- Self-improvement: violations become new rules
- Used daily by cross-functional teams on owned codebases
The False Dichotomy
The paper frames a binary choice: detailed context files (harmful) vs. no context files (better). This framing misses the third option — the one that works.
Three Approaches, Three Outcomes
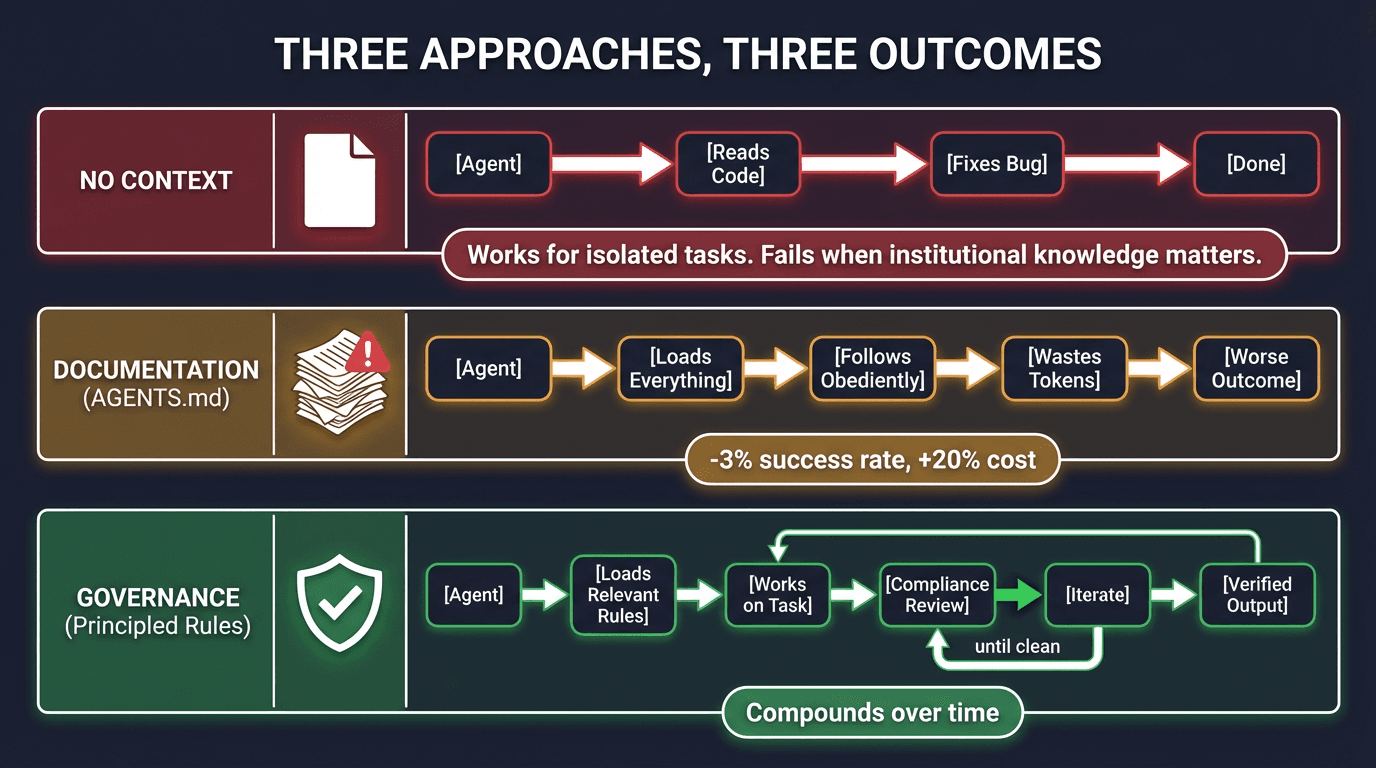
The paper inadvertently proved something important: agents with bad governance (verbose, indiscriminate AGENTS.md) perform worse than agents with no governance (no context files). This is not evidence that governance does not work. It is evidence that bad governance is worse than none — a conclusion that anyone who has worked in a poorly managed organization already knows.
The Dangerous Conclusion
What We Use Instead
Our team — engineers, designers, product managers — uses AI to generate the majority of our production code. We maintain dozens of Cursor rules, run exhaustive compliance reviews on every task, write specs before implementation, and require type-checking and linting to pass before any work is considered complete.
Here is how our approach differs from what the paper tested, and why each difference matters.
Principles, Not Descriptions
'Server until proven client.' 'Narrow, don't assert.' 'The Model IS the Service Layer.' These are not descriptions of code — they are decision frameworks that generate correct behavior in novel situations. An agent that understands WHY the team avoids type assertions makes better judgment calls than one told WHERE the TypeScript files live.
Tiered Loading, Not Monolithic Injection
Universal principles (communication standards, simplify before adding) are always active. Domain-specific rules (form handling, SDK usage, testing patterns) load when the agent's task requires them. An agent updating a blog post does not load database optimization rules. Every context token earns its place.
Enforcement, Not Suggestion
Before any task is declared complete, the compliance review triggers. The agent scans every rule, assesses semantic applicability, reads each relevant rule, and verifies compliance. The cycle repeats until clean. This is not a suggestion to follow the rules — it is a gate that blocks completion until the rules are satisfied.
Self-Improvement, Not Static Documents
When compliance review discovers a pattern violation, we create a new rule to prevent it from recurring. After a month of this cycle, most reviews complete in a single pass — the governance system has internalized the team's accumulated wisdom.
Cross-Functional Contribution, Not Engineer-Only Context
Our governance system enables designers, product managers, and marketers to contribute code safely. The rules do not care who prompted them — they care whether the output complies. This is a capability AGENTS.md was never designed for, because it was designed for engineers describing codebases to other engineers.
The Context That Actually Matters
The paper recommends that context files should include "technical stack and intent" — and this is the one recommendation we strongly agree with. Intent is the context that matters most, and the paper barely explores it.
Our Spec-Driven Development workflow provides intent before every task: what should this feature do, what are the edge cases, what are the success criteria. The spec is a forcing function for thinking — and it becomes the standard the AI's output is measured against.
Teams that plan before prompting see 6x better results than teams that prompt first and fix later. This is not a context file — it is a workflow that provides the right context at the right time.
The Context Hierarchy
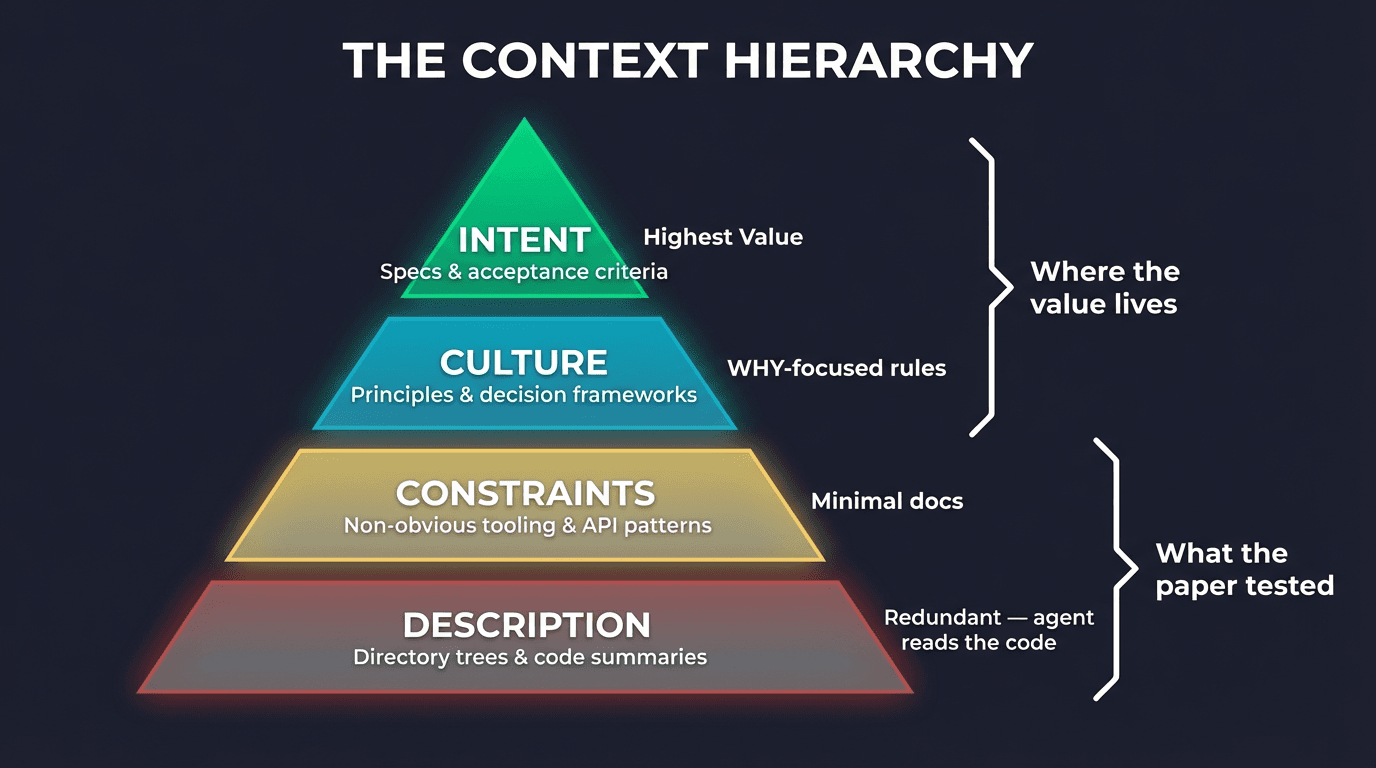
The paper tested only the bottom two tiers. It concluded that context does not help. We use all four tiers — and the top two are where the value lives.
What to Do With This Research
If you are maintaining context files for AI agents, the paper provides useful guidance — just not the guidance people think. Here is what it actually tells you:
Stop Doing
- Auto-generating context files with AI
- Including directory trees and file listings
- Duplicating style guides that linters enforce
- Loading everything into every session
- Writing context files with no enforcement mechanism
Start Doing
- Encode principles that explain WHY, not WHAT
- Use tiered loading — universal vs. domain-specific
- Build enforcement at task completion, not just load time
- Create new rules from discovered violations
- Write specs before prompting — intent is the highest-value context
The ETH Zurich paper asked a good question: do context files help AI agents? The answer they found — that monolithic documentation files loaded indiscriminately make things worse — is correct. The conclusion being drawn — that AI agents should operate without governance — is dangerous.
Documentation describes your codebase. Governance encodes your team's judgment. One is redundant with the code. The other is irreplaceable. Do not confuse them.
Build governance that compounds over time
Our team maintains 40+ Cursor rules, runs exhaustive compliance reviews, and creates new rules from every discovered violation. If you're building AI agent governance that goes beyond static documentation, I'm happy to share what we've learned.